单用模板方法带来的问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| public UserInfoDTO getUserInfo(@RequestParam("userId") String userId) {
return (new ServiceTemplate<String>() {
@Override
public void validParam(String request) {
if (userId == null || userId.isEmpty()) {
throw new RuntimeException("param UserId is invalid");
}
}
@Override
public UserInfoDTO doProcess(String request) {
UserBaseInfoVO userBaseInfoVO = userBaseInfoRepository.getUserBaseInfo(userId);
UserSpecialInfoVO userSpecialInfoVO = UserSpecialInfoRepository.getSpecialInfoVO(userId);
UserMoneyVO userMoneyVO = userMoneyRepository.getUserMoneyVO(userId);
List<ConsumeRecordVO> consumeRecordVOList = userConsumeRepository.getConsumeRecordVOList(userId);
Optional<ConsumeRecordVO> max = consumeRecordVOList.stream()
.max(Comparator.comparing(ConsumeRecordVO::getAmount));
ConsumeDTO maxAmountConsume = null;
if (max.isPresent()) {
ConsumeRecordVO consumeRecordVO = max.get();
maxAmountConsume = ConsumeDTO.builder()
.amount(consumeRecordVO.getAmount())
.date(consumeRecordVO.getDate())
.build();
}
DoubleSummaryStatistics total = consumeRecordVOList.stream()
.collect(Collectors.summarizingDouble(ConsumeRecordVO::getAmount));
double totalMoney = userMoneyVO.getMoney() + total.getSum();
return UserInfoDTO.builder()
.userName(userBaseInfoVO.getUserName())
.vipLevel(userBaseInfoVO.getVipLevel())
.maxAmountConsume(maxAmountConsume)
.totalMoney(totalMoney)
.build();
}
}).process(userId);
}
|
上节说到,虽然我们在架构设计上没啥大问题了,但当我们:
- 加逻辑:
getUserlnfo新增加用户优惠券信息
- 改逻辑:最贵一次消费记录要改成近一个月的
- 增加复杂判断:如果是授权了的用户,才查询余额,没有授权不能查
- 外部需要实现类中某一块代码:在另一个接口也需要查询消费记录并计算最大的一次消费
- 重复修改:在第四点基础上,所有查消费记录的方式需要换一个接口,请求和返回模型均发生变化
我们的代码都在一个文件里加,会导致代码:
- 腕肿难懂:看起来费劲,而且不同同学代码风格不一致,导致注释还可能难懂和有歧义
- 容易相互影响:太多行,一不小心改错了;又或者有依赖顺序、数据结构不能有变动
- 不好测试:为了测方法中的某一处逻辑,不得不在方法入参上引入大量无关数据进行mock。而且万一中途某一块其他逻辑判断非常复杂,那mock难度就是指数级上升
- 相同逻辑重复实现:如果想调用实现类中某处逻辑,只能将这部分代码复制粘贴。如果后续还要修改调用接口,可能会导致代码可能错、漏、不一致。修改工作量翻倍
说白了,现在业务代码都写在一起,牵一发而动全身,也就是高耦合了!
怎么解决耦合
先来看一个生活中的例子
我们家里有很多螺丝刀,但是
- 我们很少用它们——使用场景少
- 而且各个螺丝刀尺寸和类型(一字头,十字头等等)不一致——坏了的话整个螺丝刀就没用了
- 体积大、类型多——带着费劲
那维修工是怎么解决的呢?
只用一个螺丝刀柄,通过更换不同的螺丝刀头实现
- 什么螺丝都能拧——通用
- 坏了一个换一个——易更换
- 方便携带(体积小)
- 省成本
- 定制轻松
总结下来,就是我们要把功能拆细(造珠子)、组装便捷(串珠子)
流程引擎模式
造珠子 + 串珠子 => 责任链模式(非典型) => 流程引擎
流程引擎的核心思想是:将要执行的逻辑看成是一个个步骤的串接,由统一的角色来管理步骤的执行顺序,这个角色就是流程引擎。
我们用两张图来对比下使用流程引擎和常规瀑布式编码的不同。
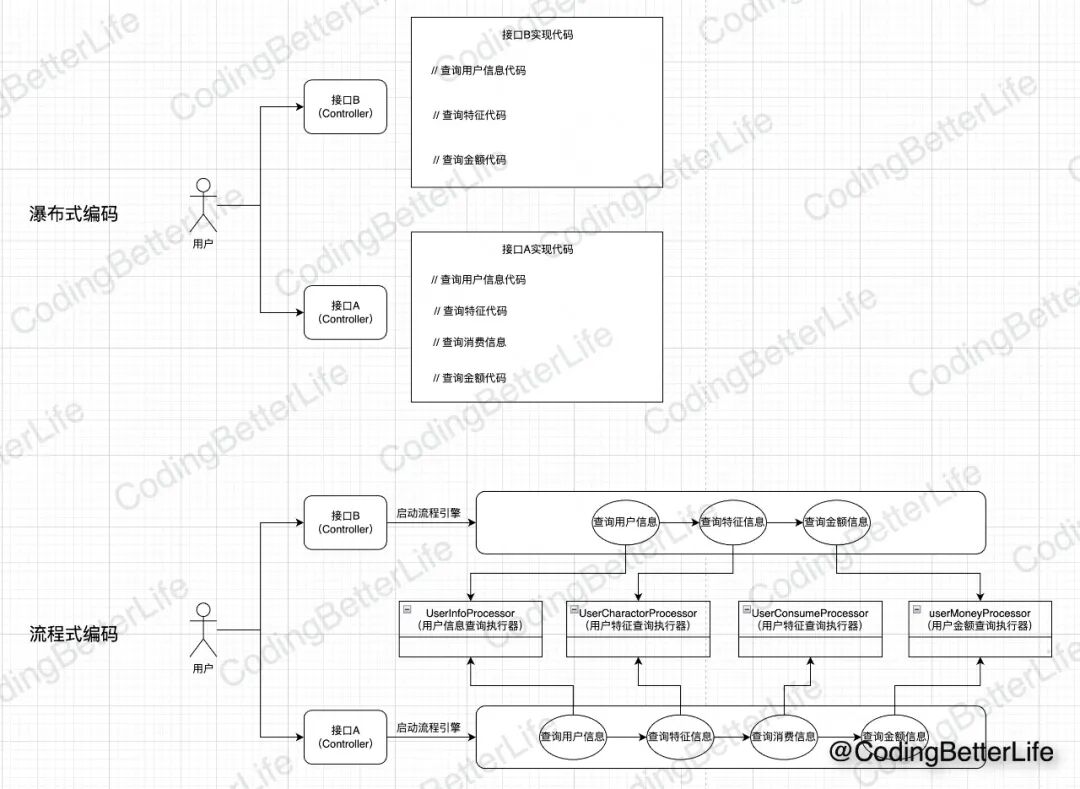
【瀑布式编码】就是从上往下按照步骤把业务逻辑写完。
【流程式编码】是先把可以独立的功能抽成一个个执行器。不同的服务根据自己功能的需求来串接这些执行器。
两者对比,流程式编码有这样一些好处:
【避免冗余】:同样的业务逻辑只有一份代码。
【最小修改】:如果需要加一个环节,只需要新增一个处理器,并且编排到流程中即可,对已有代码没有任何侵入。
【方便追踪】:我们可以在每一个节点执行完以后,在流程引擎中添加一些日志,以此来追踪执行过程。例如在哪里中断了?哪个执行器耗时最长?
【利于分工】:每个处理器约定好职责就可以独立开发,并且可以独立测试。
【可读性好】:流程式代码往往在一处编辑所有的步骤,代码可读性佳。看到一个流程由哪些节点组成,基本上就了解大概的逻辑了。
【灵活多变】:流程式编程还可以支持各个处理器以分支和循环的方式组合。
创建珠子接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public interface Processor {
boolean needExecute(ProcessRequest request, ProcessContext context);
void execute(ProcessRequest request, ProcessContext context);
}
|
创建珠子
也就是实现珠子接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
@Component
public class UserInfoQueryProcessor implements Processor {
@Autowired
private UserBaseInfoRepository userBaseInfoRepository;
@Autowired
private UserSpecialInfoRepository userSpecialInfoRepository;
@Override
public boolean needExecute(ProcessRequest request, ProcessContext context) {
return true;
}
@Override
public void execute(ProcessRequest request, ProcessContext context) {
UserBaseInfoVo userBaseInfoVo = userBaseInfoRepository.getUserBaseInfo(request.getUserId());
UserSpecialInfoVo userSpecialInfoVo = userSpecialInfoRepository.getUserSpecialInfo(request.getUserId());
context.setUserBaseInfoVo(userBaseInfoVo);
context.setUserSpecialInfoVo(userSpecialInfoVo);
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
@Component
public class MoneyProcessor implements Processor {
@Autowired
private UserMoneyRepository userMoneyRepository;
@Autowired
private UserConsumeRepository userConsumeRepository;
@Override
public boolean needExecute(ProcessRequest request, ProcessContext context) {
return true;
}
@Override
public void execute(ProcessRequest request, ProcessContext context) {
UserMoneyVo userMoneyVo = userMoneyRepository.getUserMoneyVo(request.getUserId());
context.setUserMoneyVo(userMoneyVo);
List<ConsumeRecordVo> consumeRecordVoList = userConsumeRepository.getConsumeRecordVoList(request.getUserId());
DoubleSummaryStatistics total = consumeRecordVoList.stream()
.collect(Collectors.summarizingDouble(ConsumeRecordVo::getAmount));
Double totalMoney = userMoneyVo.getMoney() + total.getSum();
context.setTotalMoney(totalMoney);
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
@Component
public class ConsumeRecordProcessor implements Processor {
@Autowired
private UserConsumeRepository userConsumeRepository;
@Override
public boolean needExecute(ProcessRequest request, ProcessContext context) {
return true;
}
@Override
public void execute(ProcessRequest request, ProcessContext context) {
List<ConsumeRecordVo> consumeRecordVoList = userConsumeRepository.getConsumeRecordVoList(request.getUserId());
Optional<ConsumeRecordVo> max = consumeRecordVoList.stream()
.max(Comparator.comparing(ConsumeRecordVo::getAmount));
max.ifPresent(context::setMaxConsume);
}
}
|
创建流程引擎接口
1
2
3
4
5
6
7
8
9
| public interface ProcessEngine {
void start(ProcessRequest request, ProcessContext context);
}
|
实现流程引擎
流程引擎只有一个start接口用来启动流程。
以下是流程引擎抽象类。抽象类除了实现对处理器执行的控制外,还可以包括日志打印、异常处理等操作。
流程引擎需要执行哪些处理器由子类决定,子类通过实现getProcessors()抽象方法来指定使用的处理器。(又是模板模式)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| public abstract class AbstractProcessEngineImpl implements ProcessEngine {
@Autowired
private Logger logger;
@Autowired
private ApplicationContext applicationContext;
@Override
public void start(ProcessRequest request, ProcessContext context) {
logger.info("processEngine start, request:" + request);
List<ProcessNameEnum> processors = getProcessors();
try {
processors.forEach(processorName -> {
Object bean = applicationContext.getBean(processorName.getName());
if (!(bean instanceof Processor)) {
logger.error("processor:" + processorName + " not exist or type is incorrect");
return;
}
logger.info("processor:" + processorName + " start");
Processor processor = (Processor) bean;
if (!processor.needExecute(request, context)) {
logger.info("processor:" + processorName + " skipped");
return;
}
processor.execute(request, context);
logger.info("processor:" + processorName + " end");
});
} catch (Exception e) {
logger.error("processEngine interrupted, e:" + Arrays.toString(e.getStackTrace()));
throw e;
}
logger.info("processEngine end, context:" + context);
}
protected abstract List<ProcessNameEnum> getProcessors();
}
|
引擎子类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
@Component
public class UserInfoQueryProcessEngine extends AbstractProcessEngineImpl {
private static final List<ProcessNameEnum> processorList = new ArrayList<>();
static {
processorList.add(ProcessNameEnum.USER_INFO_QUERY_PROCESSOR);
processorList.add(ProcessNameEnum.MONEY_PROCESSOR);
processorList.add(ProcessNameEnum.CONSUME_RECORD_PROCESSOR);
}
@Override
protected List<ProcessNameEnum> getProcessors() {
return processorList;
}
}
|
引擎子类实现getProcessors()方法即可。此方法就是告诉流程引擎具体要执行的执行器列表及执行顺序。
如果你走读代码到这里,看到list里放的三个处理器名称,你基本上就知道“用户查询接口”提供了怎样的功能。这就是良好的可读性。
试想,如果有一天,一个流程中需要新增一个逻辑,我们可以包装一个新的处理器,然后添加到上图中的processorList中即可。
每个接口都可以实现一个如上截图的引擎子类,用以编排需要执行的处理器。
特点:逻辑拆细,便捷组装
- 改一个处理器,直接在全部地方生效
- 处理器添加、调用和测试方便
典型责任链模式
之前我们提到流程引擎是非典型的责任链模式,那什么是一个典型的责任链模式?
对于一个典型的责任链
- 它的执行流程是
node1 or node2 or node3,只要有一个节点处理就可以了。不处理就给下一个,处理完了直接返回,有些像else-if的逻辑
- 每个节点自己指定了它的下一个节点
而对于流程引擎来说
- 它的执行流程是
node1 and node2 and node3,所有节点都要执行(needExecute方法本质上也是走到了节点里面)
- 引擎驱动,开发者编排执行流程
流程引擎中的SOLID
- S(单一职责原则):每个“珠子”职责清晰
- O(开闭原则):业务逻辑新增则新增“珠子”
- D(依赖倒置原则):流程引擎执行的是抽象的“珠子接口”,具体“珠子”是使用时注入
拆的太猛过犹不及
如果拆分过细,会导致编排复杂、难以管理。而且某些子逻辑很可能会被重复实现
我们很难清楚我们的系统会不会过度设计,毕竟那是未来的事。
所以我们可以尽量先不拆的那么细,但是要让系统保持继续拆分的灵活性
参考资料
[^1]: 【学架构也可以很有趣】【“趣”学架构】- 3.搭完架子串珠子
[^2]: 【成为架构师】8. 成为工程师 - 搭建系统先搭建框架
